B2B Lead Generation Services
Helping technology marketers reach the right buyers, generate demand, and drive pipeline.
Explore All →



Who We Serve
Helping technology marketers connect with the right buyers in competitive markets.
Explore All →





In part 1 of this series, I discussed a typical dual-site scenario where storage replication is used to synchronously mirror a volume or LUN object between data centers.
The goal is to mitigate the risk of data center failure. While it does that in some ways by creating multiple copies of data, the failover process is complex, depending on the scenario. Data can become corrupt, and systems can become isolated. There is no room for error in this design process.
Bad SAN design occurs from time to time in the industry, and can maybe contribute to bad feeling against shared storage platforms. My view is that much of the problem comes from not designing for scalability moving forward, thus introducing an unmanageable beast. As the environment expands, performance gets worse. This is often due to aforementioned bad design, rather than a threshold or limit reached on the controllers, for example.
In this case we also have to design for HA and FT from a storage perspective.
Let's revisit the idea of using Software RAID over distance, to see how these challenges can be met. There is nothing new in this technology – in fact it's pretty old – but we're once again using Software to solve problems, where once people had moved back to hardware-based solutions.
Here's a picture of an alternative architecture.
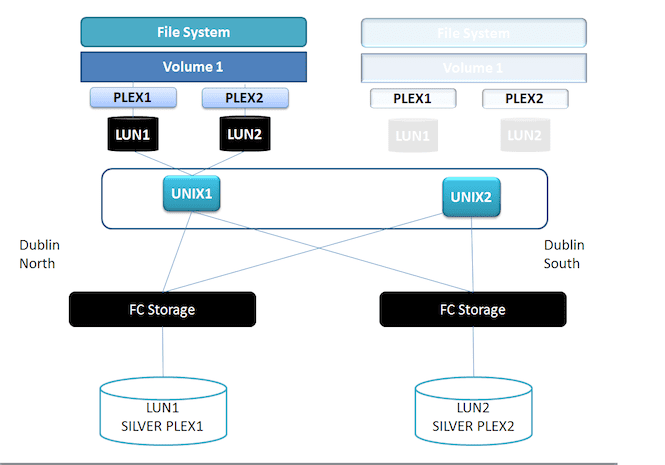 In this case Dublin South CPU resources on the cluster are alive, but in standby mode from a compute perspective.
In this case Dublin South CPU resources on the cluster are alive, but in standby mode from a compute perspective.
Let's use cross-site mirroring via software RAID. Veritas used the concept of a plex which was just a mirror unit, or unit of protection. In this scenario, we present a same block-size LUN from each site, build a plex on top of each, and then create a volume on top. From this we provision a file system.
It's not that different really to vSphere, except for the Plex object. It’s this extra layer that allows us to achieve another level of control.
The benefit of this topology is that each storage device in both arrays is always read-write – after all its just JBOD. And there's never a concept of split-brain or manual intervention. That is within the domain of software. If a mirror goes offline, you fix it, reattach and resync. Just like in the old days.
Also you can use RAID-1 for Software protection on top of RAID-5/6 inside the array. So you have increased the resilience of your solution.
The VCS solution used SCSI-3 persistent reservations for lock management at volume level, and didn't need the concept of a Witness, which made the architecture simpler than solutions requiring tiebreaker sites. In a clustered filesystem like VMFS, which is accessed by multiple hosts for multiple VMs, there are other complications.
However, aside from the locking question, which is non-trivial, this solution is resilient against:
In all these scenarios the Administrator doesn’t need to intervene.
I had a customer who was a major Irish Financial Institution that that had 30–40 stretch clusters (across HP-UX, AIX, Solaris and Windows) like this. They completed a data centre migration to bring a new data center on-stream for these clusters. They used a third plex to mirror all data to the third data center SAN, then "detached" the redundant mirror non-disruptively. That was the easiest data center migration I've ever seen. Despite the cost of entry, the low latency non-blocking characteristics of FC lend itself to solutions like this one.
Now I'm not saying this was simple or inexpensive. There was push-back by vendors against software RAID, due to perceived CPU overhead and doing something in software that should have been accomplished in hardware.
There is also a fair argument that these were complex to manage, required specialist training and were expensive to implement, both in terms of software and manday effort.
But I just wanted to point out some benefits, and I think VMware has shown that HA and other technology that would have been gruesome to implement, is now 7 or 8 clicks. We have observed of late how decoupling functionality from hardware to software is here today and prevalent across all technology pillars.
VMware VSAN is a case in point and uses something akin to software RAID. Look at these basic VSAN features:
Now, going back to the original scope of this post…
In terms of complexity, achieving a similar solution with vSphere, and extending it to metro clusters is not trivial. A Single LUN shared between two hosts is a lot simpler to conceive than a single Datastore, with 10–15 VMs, shared between 20 nodes.
You also have many different technologies in play like SVmotion, SIOC, SDRS, and PSPs that must be considered. We are also doubling the number of paths, number of LUNs and number of IOPS.
Also, think about two ESXi hosts accessing separate VMs on the same datastore, with one ESXi host housing a VM which is mirroring and the other one accessing a VM that is not paired. Those two datastores could have only some VMs mirrored – but not all of them. So there are lots of things to consider.
However that doesn't mean that logically, this isn't a good approach. I'm sure it's better than split brain between your datacenters ?. If you have the network already for SAN replication, it's certainly do-able – Isn't it ?
This could definitely work with VSAN, now that software RAID is back in vogue.
The obvious benefit there is that we no longer need external storage, just a whopping great low-latency pipe for storage replication and access between cluster nodes, which have disk in the server chassis.
By using Ethernet we could extend a VSAN cluster and mirror a virtual datastore between DCs. At present it's not possible to keep VSAN mirrors geographically diverse and "pinned" to separate host groups in separate DCs, as you would with DRS Host Group affinity rules. The witness would also need to be considered. However, I'll bet that something akin to this feature pops out very soon and may provide a new approach that can be leveraged to create a pain-free Metro Storage Cluster.
Any thoughts? Share them in the comments!









