B2B Lead Generation Services
Helping technology marketers reach the right buyers, generate demand, and drive pipeline.
Explore All →



Who We Serve
Helping technology marketers connect with the right buyers in competitive markets.
Explore All →





Openstack is a word on many people’s lips.
The Project is just over three years old, but you can feel how it has already gained mindshare and convinced important companies and people to get behind it. It’s evident from the commitment Corporations like Red Hat, VMware and HP have shown to this Open Source Software project.
Despite its relative youth and immaturity, there are plenty of large-scale production platforms in place today running Openstack, so this is not a beta product.
The VMware Community’s own Scott D. Lowe and Kenneth Hui are heavily involved in its promotion.
This is the Openstack Mission Statement:
The OpenStack Open Source Cloud Mission: to produce the ubiquitous Open Source Cloud Computing platform that will meet the needs of public and private clouds regardless of size, by being simple to implement and massively scalable.
Openstack should present an opportunity not only for Hosting providers offering hosted Private Cloud or Public Cloud Services, but also for Enterprises, to run their own Virtualization platforms or Private Clouds.
Openstack has all the pieces you would expect a typical virtualization platform to possess.
One difference is that it is a more modular architecture with different streams producing individual “products”, so to speak. That’s the Open Source way:
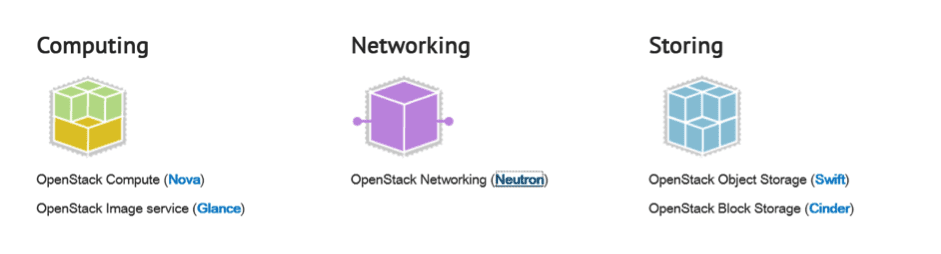
You can see from the diagram above, traditional services fall within the scope of different areas. Each area has a product or feature set name:
There are other key components within the framework:
Here’s a quick mapping of Storage Services in Openstack:
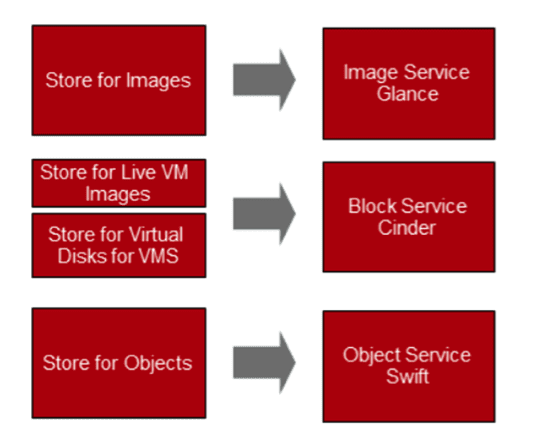
As I mentioned, Swift is not a Block or File-based Filesystem. Swift is not a POSIX-compliant block filesystem like VMFS, NTFS, ZFS or other. If you’re used to NTFS, you cannot access Swift in the same way.
It is an object store and is similar to Azure Storage Services and Amazon S3 in how it’s accessed.
It is managed directly by applications via REST HTTP APIs. This allows applications to consume it using API calls like GET, PUT, POST and DELETE.
Simply put, it uses HTTP to allow applications to talk to it.
However, a person cannot copy and paste a file to an Object Storage System or Object Store.
Swift is a resource that can (and must) be consumed and managed by Applications. This is the fundamental difference when working with REST API versus traditional Block and File-based Filesystems.
This is why application developers are much more involved with design and deployment already on Amazon S3.
One major advantage of RESTful Object Storage systems is that you can consume them from anywhere. After all, they are available over HTTP and that is the Internet’s mother tongue.
VMware VSAN is also based on an Object Store architecture but is not accessible via REST API. VSAN surfaces it’s resource (a VSAN datastore) to its attached vSphere cluster for consumption.
You should be aware that at present, Swift scale-out clusters do not present a unified filesystem made up of disk from all nodes in the cluster. Virtual Machines address disk in their local servers chassis. This is a major weakness of Swift at present.
One thing that is acknowledged is that it’s better not to try to deploy it off the shelf. Use a service provider who can translate your requirements into reality, without having to hire your own team of developers.
Cinder is similar to a traditional block-based filesystem. It is accessed using volumes presented to Openstack hosts.
This is how access would work from the Virtual Machine layer (Nova):
One nice feature is that Cinder Backup can copy data from a volume out onto Swift.
Most people consume Cinder via non-Fibre Channel interfaces as it’s more economical. However you can use EMC, HP and other, using a specific Cinder driver for each storage system.
These three questions might help evaluate the potential impact of Openstack in the Enterprise:
What is hugely significant is that there is already an end-to-end solution stack that will compete with Amazon Web Services, driven entirely by the Open Source Community, with a little sprinkling of vendor dust.









