B2B Lead Generation Services
Helping technology marketers reach the right buyers, generate demand, and drive pipeline.
Explore All →



Who We Serve
Helping technology marketers connect with the right buyers in competitive markets.
Explore All →





This week, Gestalt IT hosted a number of bloggers and analysts at Storage Field Day 4. One of the companies that we visited was Nimble Storage, a soon-to-be public that was actually launched at a previous Tech Field Day event. Nimble discussed with us a couple of important topics: Scale Out and Big Data.
Nimble began their session with a presentation by Umesh Maheshwari (Founder and CTO) around the company’s new scaling opportunities. He indicated that many vendors provide scale up capabilities, which provides scaling of resources in just a single dimension. While simple to implement, it can only scale to a point and eventually requires a forklift upgrade to get to the next scale unit. With scale out, on the other hand, all resources are scaled in all dimensions, enabling the product to refresh perpetually. But, while scale out is often a desired feature, it’s tough for vendors to create all of the constructs that are necessary to enable all of the nodes to act as a cohesive, singular whole.
Nimble has taken the approach that both approaches have a place in the enterprise and, personally, I believe they’re spot on. Many organizations have light duty I/O needs, but really high capacity needs. For these organizations, a scale up approach makes perfect sense and can save a lot of money. For others, they may need both high I/O and high capacity. These customers would quickly outstrip the resource potential in a single node, so having the ability to scale to four nodes in a cluster makes sense.
On the scale up front, Nimble enables these scenarios:
When it comes to scale out, Nimble enables customers to scale capacity and performance by grouping any combination of hybrid arrays to form a scale-out storage cluster. Nimble supports up to four nodes in a cluster. In a fully built-out cluster, up to sixteen disk shelves can exist. This is a far cry from the company’s already substantial v1 efforts and is a great step forward.
You may wonder why Nimble only scales to four nodes. At present, the company has taken a very important first step in achieving scale out in a way that enables an increase in both performance and capacity. Nimble chops up data into small slices and stripes them across node members. In doing so, Nimble can leverage all of the CPU, all of the network, and all of the spindles of all nodes, ensuring linear resource scalability. However, all fault tolerance still takes place at the node level. Bear in mind that each individual node is engineered to be highly available and Nimble indicates that their customers enjoy greater than 99.999% uptime. However, for volumes that use this slicing technique, if any node fails, the entire volume in inaccessible.
I asked Nimble if this was because they’re just kicking off their scale out efforts and they indicated that this was the case. Over time, they will build more substantial data protection mechanisms that allow customers to eventually scale well beyond just four nodes. In other words, they had to start somewhere, so they did. The primary downside to the approach is that the possibility of a failure for sliced volumes can be up to four times greater than for volumes the reside on a single volume alone, but with availability metrics better than 99.999% per node, the risk is still reasonable.
Scale to Fit has been released, but is not yet fully generally available.
Scale out has been a critical need for Nimble. Without it, the company would have been relegated to the SMB and small midmarket. But, what I’m even more excited about is InfoSight. Last year, I was just about as excited by what I saw from HP’s Gen 8 servers in which HP introduced comprehensive, phone-home instrumentation. The sensors constantly gather data and send that data to HP. In fact, when a customer calls HP, there’s a good chance that the support tech will know more about the issue than the customer.
Consider the traditional support approach:
InfoSight is Nimble’s big data answer to improving overall customer support and satisfaction, not to mention availability. Each Nimble array sends a heartbeat to Nimble HQ every five minutes. The heartbeat packet includes statistics about temperature, overall disk health, replication status, and a whole lot more. Each day, the array sends a more comprehensive set of stats back to Nimble as well. 30 million sensors (or more!) per array per day are reported to Nimble HQ. All of this information is pushed into the InfoSight engine.
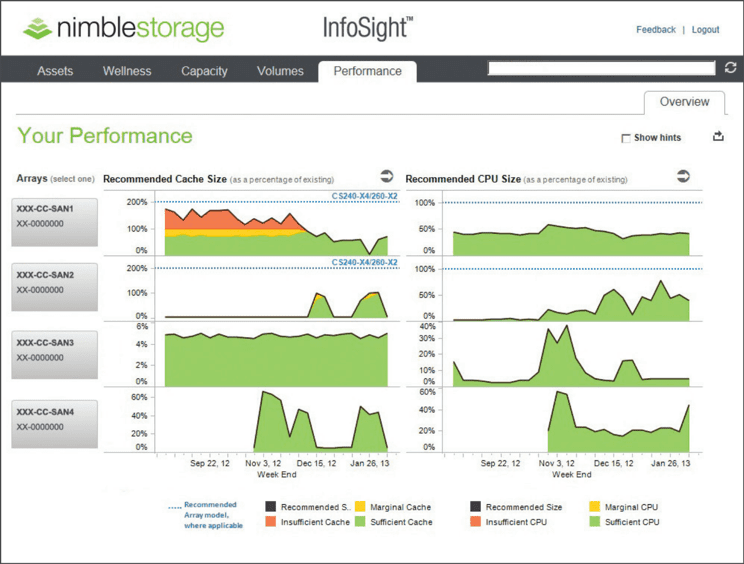
Customers have access to all of this information via the InfoSight portal. More importantly, though, once Nimble has all of this information, it becomes simpler to determine root cause issues and even take proactive steps to avoid issues. For example, suppose Customer A has seen an issue that is the result of a particular configuration. Nimble can query InfoSight to determine what other customers might be susceptible to the same issue. In this service which Nimble calls Proactive Wellness, Nimble will open a ticket automatically for the customer and help them resolve the issue before it becomes a problem. In addition, Nimble can notify the customer of other situations as well, such as:
In fact, Nimble was able to quickly identify a software bug in their code because of the information that was being gleaned from real-world customer environments. Developers were able to quickly fix the code and, based on all of their metrics, reached out to customers with a fix in the order in which Nimble thought that they would be affected.
Personally, I believe that these kinds of solutions are absolutely critical for overworked IT departments. Any kind of partnership that can proactively correct issues in critical infrastructure is a boon.
In addition, the way that Nimble is leveraging Big Data is a perfect example of how Big Data can be leveraged to boost the bottom line and improve key metrics in various lines of business. In Nimble’s case:
Nimble has taken a really good first step in scaling their architecture and I look forward to seeing where they take it next. With the current solution, Nimble has opened up a huge new market that needed more aggregate capacity and performance than could be supported before. Further, with InfoSight, Nimble has made sure that they have all of the data they need in order to continually — and proactively — support there customers while also helping to identify future development activities.









