B2B Lead Generation Services
Helping technology marketers reach the right buyers, generate demand, and drive pipeline.
Explore All →



Who We Serve
Helping technology marketers connect with the right buyers in competitive markets.
Explore All →





Even as disk capacities continue to increase, data storage vendors are constantly seeking methods by which their customers can cram ever-expanding mountains of data into storage devices. After all, even with bigger disks, it just makes sense to explore opportunities to maximize the potential capacity of those disks.
To this end, storage vendors rely on two major technologies – compression and deduplication. These storage features are often clumped into a broader category called “data reduction” technologies, but the end result is the same: Customers are able to effectively store more data than the overall capacity of their storage systems would suggest. For example, if a customer has a 10 TB storage array and that customer is getting a five to 1 (5:1) benefit from various data reduction mechanisms, it would be theoretically possible to storage 50 TB worth of data on that array.
With that in mind, let’s explore one of the most popular data reduction mechanisms: Deduplication.
Consider this scenario: Your organization is running a virtual desktop environment with hundreds of identical workstations all stored on an expensive storage array that was purchased specifically to support this initiative. So, you’re running hundreds of copies of Windows 8, Office 2013, your ERP software, and any other tools that your users might require. Each individual workstation image consumes, say, 25 GB of disk space. With just 200 such workstations, these images alone would consume 5 TB of capacity.
With deduplication, you can store just one copy of these individual virtual machines and then allow the storage array to simply place pointers to the rest. Each time the deduplication engine comes across a piece of data that is already stored somewhere in the environment, rather than write that full copy of data all over again, the system instead saves a small pointer in the data copy’s place, thus freeing up the blocks that would have otherwise been occupied. In the figure below, note that the graphic on the left shows what happens without deduplication. The graphic at the right shows deduplication in action. In this example, there are four copies of the blue block and two copies of the green block stored on this array. Deduplication enables just one block to be written for each block, thus freeing up those other four blocks.
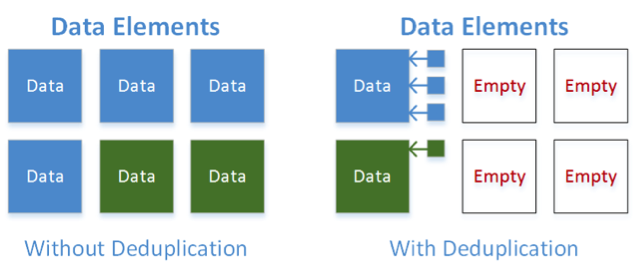
Now, expand this example to a real world environment. Imagine the deduplication possibilities present in a VDI scenario. With hundreds of identical or close to identical desktop images, deduplication has the potential to significantly reduce the capacity needed to store all of those virtual machines.
Deduplication works by creating a data fingerprint for each object that is written to the storage array. As new data is written to the array, if there are matching fingerprints, additional data copies beyond the first are saved as tiny pointers. If a completely new data item is written – one that the array has not seen before – the full copy of the data is stored.
As you might expect, different vendors handle deduplication in different ways. In fact, there are two primary deduplication techniques that deserve discussion: Inline deduplication and post-process deduplication.
Inline deduplication takes place at the moment that data is written to the storage device. While the data is in transit, the deduplication engine fingerprints the data on the fly. As you might expect, this deduplication process does create some overhead. First, the system has to constantly fingerprint incoming data and then quickly identify whether or not that new fingerprint already matches something in the system. If it does, a pointer to the existing fingerprint is written. If it does not, the block is saved as-is. This process introduces the need to have processors that can keep up with what might be a tremendous workload. Further, there is the possibility that latency could be introduced into the storage I/O stream due to this process.
A few years ago, these might have been showstoppers since some storage controllers may not have been able to keep up with the workload need. Today, though, processors have moved far beyond what they were just a few years ago and these kinds of workloads don’t have the same negative performance impact that they might have once had. In fact, inline deduplication is a cornerstone feature for most of the new storage devices released in the past few years and, while it may introduce some overhead, it’s not that noticeable and provides far more benefits than costs.
As mentioned, inline deduplication imposes the potential for some processing overhead and potential latency. The problem is that the deduplication engine has to run constantly, which means that the system needs to be adequately sized with constant deduplication in mind. Making matters worse, it can be difficult to predict exactly how much processing power will be needed to achieve the deduplication goal. As such, it’s not always possible to perfectly plan overhead requirements.
This is where post-process deduplication comes into play. Whereas inline deduplication processes deduplication entries as the data flows through the storage controllers, post-process deduplication happens on a regular schedule – perhaps overnight. With post-process deduplication, all data is written in its full form – copies and all – and on that regular schedule, the system then goes through and fingerprints all new data and removes multiple copies, replacing them with pointers to the original copy of the data.
Post-process deduplication enables organizations to utilize this data reduction service without having to worry about the constant processing overhead involved with inline deduplication. This process enables organizations to schedule dedupe to take place during off hours.
The biggest downside to post-process deduplication is the fact that all data is stored fully hydrated – a technical term that means that the data has not been deduplicated – and, as such, requires all of the space that non-deduplicated data needs. It’s only after the scheduled process that the data is shrunk. For those using post-process dedupe, bear in mind that, at least temporarily, you’ll need to plan on having extra capacity.
Deduplication can have significant benefits when it comes to reducing overall storage costs, but it’s important to understand the two major types of deduplication so that appropriate upfront planning can take place.









