B2B Lead Generation Services
Helping technology marketers reach the right buyers, generate demand, and drive pipeline.
Explore All →



Who We Serve
Helping technology marketers connect with the right buyers in competitive markets.
Explore All →





Hyper-V admins take note: there is a new solution on the market for you! This week, Gridstore announced their Hyper-V-based hyperconverged infrastructure solution. Far from being just a “me too” in the red-hot hyperconverged market, Gridstore appears to have taken things to a whole new level, and not just by supporting Hyper-V. I have not yet talked to Gridstore about their solution, but have spent time studying their materials that are available at their web site and if reality lives up to what I read, Gridstore’s phones should be ringing off the hook.
While everyone else in the market was focusing on virtualization king VMware, Gridstore has been chugging away supporting Microsoft’s Hyper-V virtualization platform. Up until now, Gridstore has produced simple, scalable storage arrays for these environments and has attached itself to the software defined storage trend.
Today, the market is changing, and changing fast. Of course, storage remains critically important, but hyperconvergence – the melding of servers and storage – has hit the market with a vengeance. This new space was propelled by VMware’s announcement of EVO:RAIL at VMworld in August of 2014.
Gridstore has jumped in with both feet, but with a couple of big twists.
As you look at the hyperconverged infrastructure market, it’s obvious that parity is dead… or at least it was on life support. Many hyperconvergence vendors, in order to avoid the processing overhead that comes with parity calculations, have eliminated any kind of RAID and parity in favor of taking a replica-based approach to data protection. In essence, each bit is written three separate times to different places in the cluster. If one or two copies fail or are affected by a hardware outage, there is still a third copy out there that can be used for recovery.
Of course, this approach means that three times the storage capacity is needed in order to achieve data protection goals. This is a fundamental tradeoff between capacity and overall performance. You are basically trading terabytes for IOPS, but there is still processing overhead in creating all of those replicas. To be clear, I’m not knocking the approach at all; it’s perfect valid and is a proven methodology.
Gridstore, however, uses a parity-based scheme for their own implementation. The graphic below is right from Gridstore and demonstrates their approach to data protection.
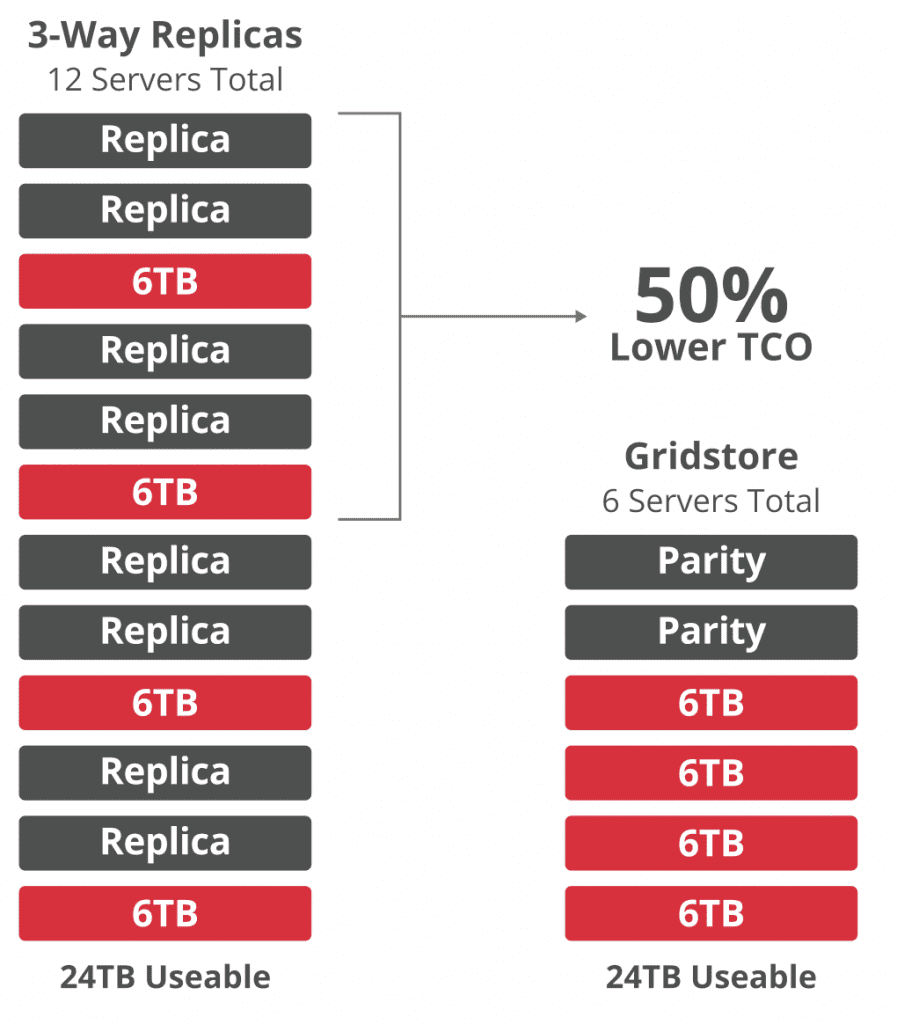
On the surface, this is a good thing as it can help organizations move forward with a solution that could be more cost efficient. That said, I have not yet had the opportunity to consider potential parity-induced overhead that could result. There are always tradeoffs between different data protection approaches. The question is this: if there is, in fact, parity overhead, is it significant enough to outweigh the cost benefit to be had from needing less storage?
Perhaps the biggest challenge around hyperconvergence is having to ask the question “Do I need to be 100% hyperconverged or can I mix and match?” The answer to this question is “it depends”. Each vendor in the space supports different integration and coexistence options. But, until now, none have brought to market a solution that enables linear scalability of the converged environment while also providing more traditional siloed resources still managed within the context of the aggregated environment.
Gridstore appears to be going this route.
The company’s hyperconverged appliances sit alongside and participate actively with their traditional storage offerings. The question is this: is the entire combined environment managed centrally? I doubt that the dedicated compute nodes would be managed centrally as the only Gridstore component there is the vController, but that needs validation.
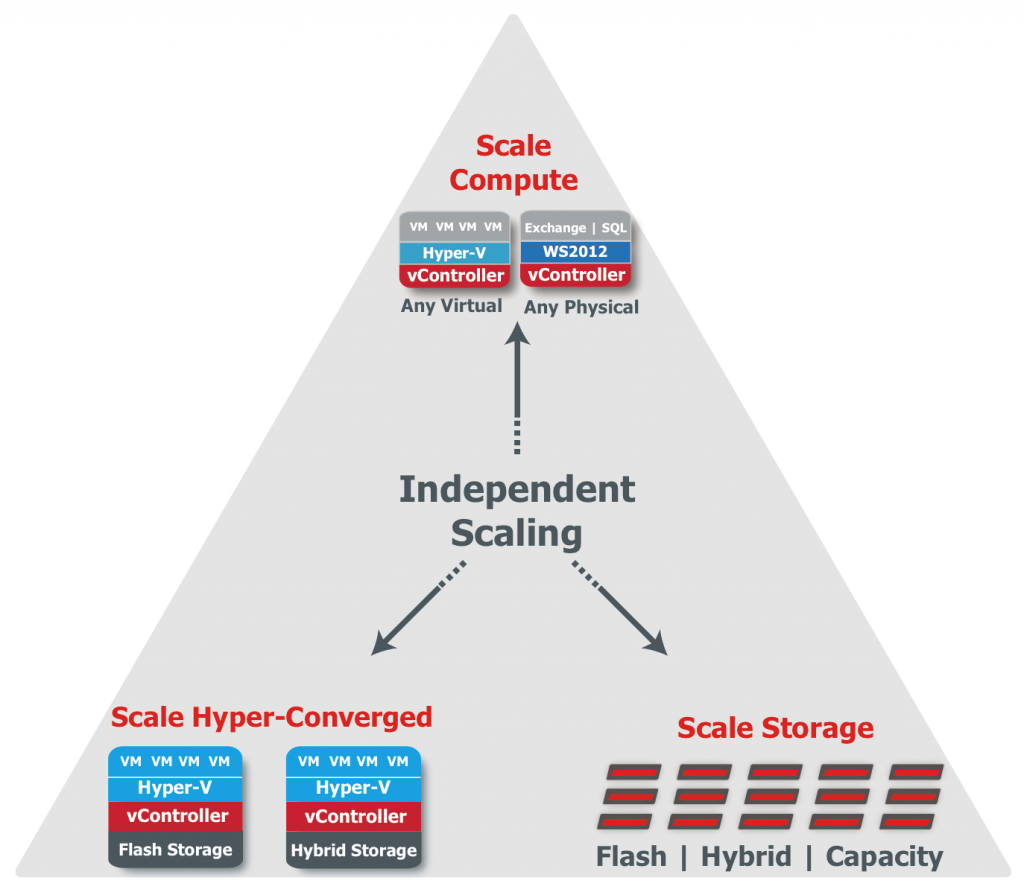
I also don’t know how far Gridstore has taken the non-hardware integration. Is the full hyperconverged environment – VM creation, etc. – managed in the same environment as the storage component? Are administrators shielded from storage complexity as is the case in other hyperconverged infrastructure scenarios? It’s the streamlined administration paradigm that defines hyperconvergence.
I’m certainly impressed by Gridstore’s jump into this space with a product that appears truly differentiated from the rest of the (growing) crowd. I look very forward to an opportunity to put the solution to the test to get answers to some of the questions that I’ve raised in this article.









