B2B Lead Generation Services
Helping technology marketers reach the right buyers, generate demand, and drive pipeline.
Explore All →



Who We Serve
Helping technology marketers connect with the right buyers in competitive markets.
Explore All →





Coho Data, one of the newly unveiled start-ups focused on providing scale-out storage, sends their CTO Andy Warfield to tackle a group of cutting-edge tech bloggers and analysis during Storage Field Day 4. The results were spectacular – getting into the science behind the technology during mini deep dives, coupled with demonstrations of the product, served to satiate the appetites of the delegates – including myself. Here’s why you should keep an eye on a company that can mix up software defined networking with a scale-out storage architecture.
The term “Software Defined Networking” or SDN has reached a level of fervor that causes most tech professionals to quickly tune out from a buzz overload. Being one of those people myself, I would cite the reason being the lack of solid use cases. Apparently all the best IT shops are using software defined networks so I need to, too – right?
I don’t doubt that there are environments that take advantage of the OpenFlow Standard as a piece of the puzzle to create a software defined network. But most marketing companies simply stress the message that SDN is required for success, but tend to get fuzzy on exactly what that means.
Coho Data has come to the table with a concrete example of how to use OpenFlow to provide scale-out, high performance storage MicroArrays and their DataStream Architecture. The client compute layer, such as a vSphere host, connects to a single IP namespace and mounts storage using the Network File System (NFS) protocol. This mount connection is transparently intercepted and interrogated by a pair of OpenFlow enabled, commodity Ethernet switches. The switches also have a connection to every Coho DataStream node along with real-time understanding of utilization, data locality, and IO performance.
OpenFlow is used to dynamically assign a vSphere host connection to a DataStream MicroArray node. Because data is fluid, the switches can react to change – such as increased stress on a node or even the failure of an entire node – and change the mapping between a vSphere host and the back-end DataStream node. Again, this is all transparent to the vSphere host and requires no fiddling with drivers or administrative configuration. The figure below shows a 10 node configuration, in which 2 of the nodes have recently been added. The green lines show how data is being remapped to the new nodes, and the SDN switch may decide to seamlessly shift around vSphere host connections.

Because each MicroArray has containers a pair of high performance Intel PCIe flash and six high capacity SATA disks, horsepower is hardly a limitation. It would seem that the only scale-out limitation is the quantity of ports on the upstream pair of commodity switches, which is 52 ports today, and any arbitrary “we haven’t tested it yet” barriers that Coho Data may want to enforce as their deployment base increases. Knowing that most arrays can only scale out to 2, 4, or 8 nodes, the idea of having 20+ nodes behind one addressable IP is quite good.
Deploying storage into the enterprise isn’t just an exercise of getting a solution into production. That’s actually the easy part – net-new installations are a cake walk. The hard part is trying to figure out where performance bottlenecks are cropping up, when to scale a system up or out, and how effective the scaling will be. Using in-system analytics, Coho’s DataStream Architecture aims to provide a friendly GUI front end to answer all of these questions.
Take the figure below, for example. A mixed workload of high performance database servers and virtual desktops are using the same back end storage – the DataStream MicroArrays. The Coho team has ran some brutally crushing tests on them to simulate all sorts of “worst case” scenarios, as evident by all the red and orange indicators at various time points.
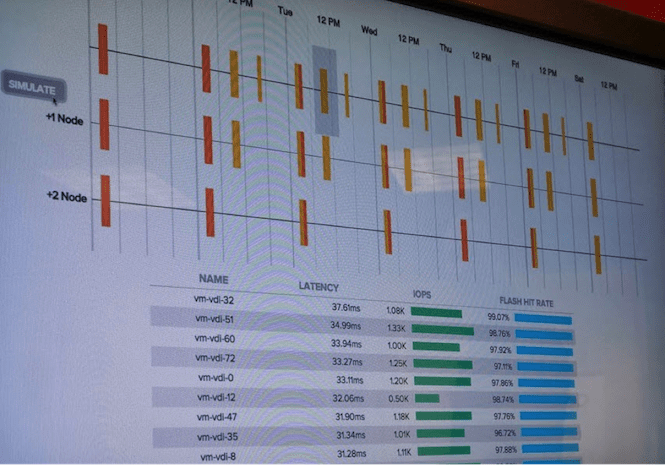
By using IOPS tracing, which is very non-stressful to the MicroArray, an analytics engine kicks in during idle periods to better understand, model, and forecast performance in a variety of what-if scenarios. By pressing the simulate button, another pair of graphics appear showing the same historical performance data with a twist – what if there had been +1 or +2 more MicroArray nodes available? How would performance have changed?
As someone who is responsible for justifying additional IT spend, you can easily review all of the pain points over a time interval and understand what workloads are affected. In this case, all of the virtual desktop pain points are completely eliminated by adding +2 nodes, while the SQL database workload remains roughly the same. There’s no use in throwing more hardware at the SQL problem, and in this case it’s due to the fact that the brutal workload test was designed to be unsolvable (and thus non real-world). If you do wish to approach the management team for additional IT spend, you will be armed with a relatively solid idea as to what performance will look like prior to cutting the PO.
Coho Data has taken managed to saddle a rather intangible concept, software defined networking, and use it as the keystone of their storage solution. Their approach to working with the NFS protocol and OpenFlow is refreshingly simple yet full of promise. There’s still work to be done to add all of the enterprise features needed to play in the SME and Enterprise arenas, such as replication and snapshots. However, given the smarts employed by the company, I don’t see these being difficult challenges to tackle.









